











Crawl4AI v0.2.3 🕷️🤖





Crawl4AI has one clear task: to simplify crawling and extract useful information from web pages, making it accessible for large language models (LLMs) and AI applications. 🆓🌐
- Use as REST API: Check

- Use as Python library:
Recent Changes
v0.2.3
- 🎨 Extract and return all media tags (Images, Audio, and Video). Check
result.media - 🔗 Extrat all external and internal links. Check
result.links - 📚 Extract metadata from the page. Check
result.metadata - 🕵️ Support
user_agentparameter to set the user agent for the HTTP requests. - 🖼️ Take screenshots of the page.
v0.2.2
- Support multiple JS scripts
- Fixed some of bugs
- Resolved a few issue relevant to Colab installation
v0.2.0
- 🚀 10x faster!!
- 📜 Execute custom JavaScript before crawling!
- 🤝 Colab friendly!
- 📚 Chunking strategies: topic-based, regex, sentence, and more!
- 🧠 Extraction strategies: cosine clustering, LLM, and more!
- 🎯 CSS selector support
- 📝 Pass instructions/keywords to refine extraction
Power and Simplicity of Crawl4AI 🚀
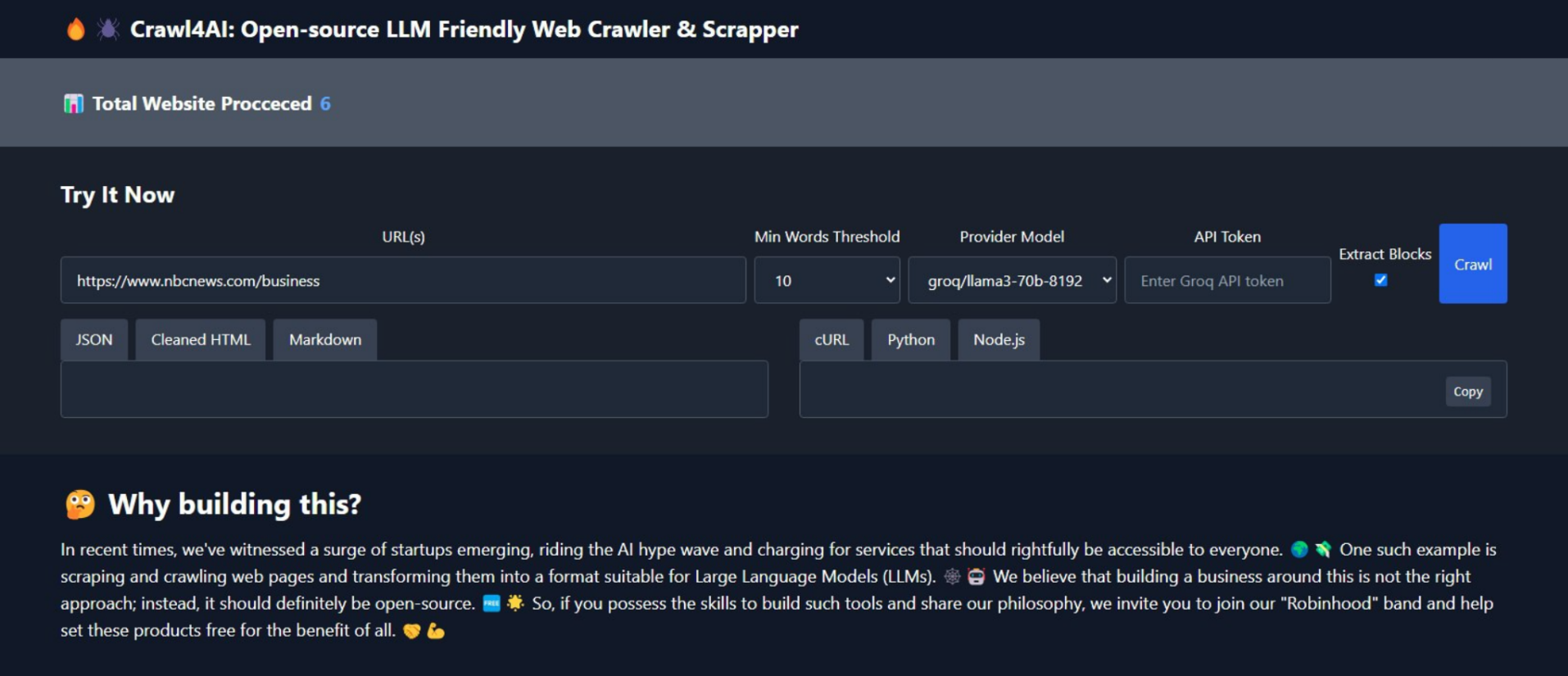
The most easy way! If you don’t want to install any library, you can use the REST API on my server. But remember, this is just a simple server. I may improve its capacity if I see there is demand. You can find ll examples of REST API in this colab notebook. ![]()
import requests
data = {
"urls": [
"https://www.nbcnews.com/business"
],
"screenshot": True
}
response = requests.post("https://crawl4ai.com/crawl", json=data) # OR local host if your run locally
response_data = response.json()
print(response_data['results'][0].keys())
# dict_keys(['url', 'html', 'success', 'cleaned_html', 'media',
# 'links', 'screenshot', 'markdown', 'extracted_content',
# 'metadata', 'error_message'])But you muore control then take a look at the first example of using the Python library.
from crawl4ai import WebCrawler
# Create the WebCrawler instance
crawler = WebCrawler()
# Run the crawler with keyword filtering and CSS selector
result = crawler.run(url="https://www.nbcnews.com/business")
print(result) # {url, html, cleaned_html, markdown, media, links, extracted_content, metadata, screenshots}Now let’s try a complex task. Below is an example of how you can execute JavaScript, filter data using keywords, and use a CSS selector to extract specific content—all in one go!
- Instantiate a WebCrawler object.
- Execute custom JavaScript to click a “Load More” button.
- Extract semantical chunks of content and filter the data to include only content related to technology.
- Use a CSS selector to extract only paragraphs (
<p>tags).
# Import necessary modules
from crawl4ai import WebCrawler
from crawl4ai.chunking_strategy import *
from crawl4ai.extraction_strategy import *
from crawl4ai.crawler_strategy import *
# Define the JavaScript code to click the "Load More" button
js_code = ["""
const loadMoreButton = Array.from(document.querySelectorAll('button')).find(button => button.textContent.includes('Load More'));
loadMoreButton && loadMoreButton.click();
"""]
crawler = WebCrawler(verbose=True)
crawler.warmup()
# Run the crawler with keyword filtering and CSS selector
result = crawler.run(
url="https://www.nbcnews.com/business",
js = js_code,
extraction_strategy=CosineStrategy(
semantic_filter="technology",
),
)
# Run the crawler with LLM extraction strategy
result = crawler.run(
url="https://www.nbcnews.com/business",
js = js_code,
extraction_strategy=LLMExtractionStrategy(
provider="openai/gpt-4o",
api_token=os.getenv('OPENAI_API_KEY'),
instruction="Extract only content related to technology"
),
css_selector="p"
)
# Display the extracted result
print(result)With Crawl4AI, you can perform advanced web crawling and data extraction tasks with just a few lines of code. This example demonstrates how you can harness the power of Crawl4AI to simplify your workflow and get the data you need efficiently.
Continue reading to learn more about the features, installation process, usage, and more.
Table of Contents
- Features
- Installation
- REST API/Local Server
- Python Library Usage
- Parameters
- Chunking Strategies
- Extraction Strategies
- Contributing
- License
- Contact
Features ✨
- 🕷️ Efficient web crawling to extract valuable data from websites
- 🤖 LLM-friendly output formats (JSON, cleaned HTML, markdown)
- 🌍 Supports crawling multiple URLs simultaneously
- 🌃 Replace media tags with ALT.
- 🆓 Completely free to use and open-source
- 📜 Execute custom JavaScript before crawling
- 📚 Chunking strategies: topic-based, regex, sentence, and more
- 🧠 Extraction strategies: cosine clustering, LLM, and more
- 🎯 CSS selector support
- 📝 Pass instructions/keywords to refine extraction
Installation 💻
There are three ways to use Crawl4AI:
- As a library (Recommended)
- As a local server (Docker) or using the REST API
- As a Google Colab notebook.
To install Crawl4AI as a library, follow these steps:
- Install the package from GitHub:
virtualenv venv source venv/bin/activate pip install "crawl4ai[all] @ git+https://github.com/unclecode/crawl4ai.git"
💡 Better to run the following CLI-command to load the required models. This is optional, but it will boost the performance and speed of the crawler. You need to do this only once.
crawl4ai-download-models- Alternatively, you can clone the repository and install the package locally:
virtualenv venv source venv/bin/activate git clone https://github.com/unclecode/crawl4ai.git cd crawl4ai pip install -e .[all] - Use docker to run the local server:
# For Mac users # docker build --platform linux/amd64 -t crawl4ai . # For other users # docker build -t crawl4ai . docker run -d -p 8000:80 crawl4ai
Using the Local server ot REST API 🌐
You can also use Crawl4AI through the REST API. This method allows you to send HTTP requests to the Crawl4AI server and receive structured data in response. The base URL for the API is https://crawl4ai.com/crawl [Available now, on a CPU server, of course will be faster on GPU]. If you run the local server, you can use http://localhost:8000/crawl. (Port is dependent on your docker configuration)
Example Usage
To use the REST API, send a POST request to http://localhost:8000/crawl with the following parameters in the request body.
Example Request:
{
"urls": ["https://www.nbcnews.com/business"],
"include_raw_html": false,
"bypass_cache": true,
"word_count_threshold": 5,
"extraction_strategy": "CosineStrategy",
"chunking_strategy": "RegexChunking",
"css_selector": "p",
"verbose": true,
"extraction_strategy_args": {
"semantic_filter": "finance economy and stock market",
"word_count_threshold": 20,
"max_dist": 0.2,
"linkage_method": "ward",
"top_k": 3
},
"chunking_strategy_args": {
"patterns": ["nn"]
}
}Example Response:
{
"status": "success",
"data": [
{
"url": "https://www.nbcnews.com/business",
"extracted_content": "...",
"html": "...",
"cleaned_html": "...",
"markdown": "...",
"media": {...},
"links": {...},
"metadata": {...},
"screenshots": "...",
}
]
}For more information about the available parameters and their descriptions, refer to the Parameters section.
Python Library Usage 🚀
🔥 A great way to try out Crawl4AI is to run quickstart.py in the docs/examples directory. This script demonstrates how to use Crawl4AI to crawl a website and extract content from it.
Quickstart Guide
Create an instance of WebCrawler and call the warmup() function.
crawler = WebCrawler()
crawler.warmup()Understanding ‘bypass_cache’ and ‘include_raw_html’ parameters
First crawl (caches the result):
result = crawler.run(url="https://www.nbcnews.com/business")Second crawl (Force to crawl again):
result = crawler.run(url="https://www.nbcnews.com/business", bypass_cache=True)💡 Don't forget to set `bypass_cache` to True if you want to try different strategies for the same URL. Otherwise, the cached result will be returned. You can also set `always_by_pass_cache` in constructor to True to always bypass the cache.Crawl result without raw HTML content:
result = crawler.run(url="https://www.nbcnews.com/business", include_raw_html=False)Result Structure
The result object contains the following fields:
class CrawlResult(BaseModel):
url: str
html: str
success: bool
cleaned_html: Optional[str] = None
media: Dict[str, List[Dict]] = {} # Media tags in the page {"images": [], "audio": [], "video": []}
links: Dict[str, List[Dict]] = {} # Links in the page {"external": [], "internal": []}
screenshot: Optional[str] = None # Base64 encoded screenshot
markdown: Optional[str] = None
extracted_content: Optional[str] = None
metadata: Optional[dict] = None
error_message: Optional[str] = NoneTaking Screenshots
result = crawler.run(url="https://www.nbcnews.com/business", screenshot=True)
with open("screenshot.png", "wb") as f:
f.write(base64.b64decode(result.screenshot))Adding a chunking strategy: RegexChunking
Using RegexChunking:
result = crawler.run(
url="https://www.nbcnews.com/business",
chunking_strategy=RegexChunking(patterns=["nn"])
)Using NlpSentenceChunking:
result = crawler.run(
url="https://www.nbcnews.com/business",
chunking_strategy=NlpSentenceChunking()
)Extraction strategy: CosineStrategy
So far, the extracted content is just the result of chunking. To extract meaningful content, you can use extraction strategies. These strategies cluster consecutive chunks into meaningful blocks, keeping the same order as the text in the HTML. This approach is perfect for use in RAG applications and semantical search queries.
Using CosineStrategy:
result = crawler.run(
url="https://www.nbcnews.com/business",
extraction_strategy=CosineStrategy(
semantic_filter="",
word_count_threshold=10,
max_dist=0.2,
linkage_method="ward",
top_k=3
)
)You can set semantic_filter to filter relevant documents before clustering. Documents are filtered based on their cosine similarity to the keyword filter embedding.
result = crawler.run(
url="https://www.nbcnews.com/business",
extraction_strategy=CosineStrategy(
semantic_filter="finance economy and stock market",
word_count_threshold=10,
max_dist=0.2,
linkage_method="ward",
top_k=3
)
)Using LLMExtractionStrategy
Without instructions:
result = crawler.run(
url="https://www.nbcnews.com/business",
extraction_strategy=LLMExtractionStrategy(
provider="openai/gpt-4o",
api_token=os.getenv('OPENAI_API_KEY')
)
)With instructions:
result = crawler.run(
url="https://www.nbcnews.com/business",
extraction_strategy=LLMExtractionStrategy(
provider="openai/gpt-4o",
api_token=os.getenv('OPENAI_API_KEY'),
instruction="I am interested in only financial news"
)
)Targeted extraction using CSS selector
Extract only H2 tags:
result = crawler.run(
url="https://www.nbcnews.com/business",
css_selector="h2"
)Passing JavaScript code to click ‘Load More’ button
Using JavaScript to click ‘Load More’ button:
js_code = """
const loadMoreButton = Array.from(document.querySelectorAll('button')).find(button => button.textContent.includes('Load More'));
loadMoreButton && loadMoreButton.click();
"""
crawler_strategy = LocalSeleniumCrawlerStrategy(js_code=js_code)
crawler = WebCrawler(crawler_strategy=crawler_strategy, always_by_pass_cache=True)
result = crawler.run(url="https://www.nbcnews.com/business")Parameters 📖
| Parameter | Description | Required | Default Value |
|---|---|---|---|
urls |
A list of URLs to crawl and extract data from. | Yes | – |
include_raw_html |
Whether to include the raw HTML content in the response. | No | false |
bypass_cache |
Whether to force a fresh crawl even if the URL has been previously crawled. | No | false |
screenshots |
Whether to take screenshots of the page. | No | false |
word_count_threshold |
The minimum number of words a block must contain to be considered meaningful (minimum value is 5). | No | 5 |
extraction_strategy |
The strategy to use for extracting content from the HTML (e.g., “CosineStrategy”). | No | NoExtractionStrategy |
chunking_strategy |
The strategy to use for chunking the text before processing (e.g., “RegexChunking”). | No | RegexChunking |
css_selector |
The CSS selector to target specific parts of the HTML for extraction. | No | None |
user_agent |
The user agent to use for the HTTP requests. | No | Mozilla/5.0 |
verbose |
Whether to enable verbose logging. | No | true |
Chunking Strategies 📚
RegexChunking
RegexChunking is a text chunking strategy that splits a given text into smaller parts using regular expressions. This is useful for preparing large texts for processing by language models, ensuring they are divided into manageable segments.
Constructor Parameters:
patterns(list, optional): A list of regular expression patterns used to split the text. Default is to split by double newlines (['nn']).
Example usage:
chunker = RegexChunking(patterns=[r'nn', r'. '])
chunks = chunker.chunk("This is a sample text. It will be split into chunks.")NlpSentenceChunking
NlpSentenceChunking uses a natural language processing model to chunk a given text into sentences. This approach leverages SpaCy to accurately split text based on sentence boundaries.
Constructor Parameters:
- None.
Example usage:
chunker = NlpSentenceChunking()
chunks = chunker.chunk("This is a sample text. It will be split into sentences.")TopicSegmentationChunking
TopicSegmentationChunking uses the TextTiling algorithm to segment a given text into topic-based chunks. This method identifies thematic boundaries in the text.
Constructor Parameters:
num_keywords(int, optional): The number of keywords to extract for each topic segment. Default is3.
Example usage:
chunker = TopicSegmentationChunking(num_keywords=3)
chunks = chunker.chunk("This is a sample text. It will be split into topic-based segments.")FixedLengthWordChunking
FixedLengthWordChunking splits a given text into chunks of fixed length, based on the number of words.
Constructor Parameters:
chunk_size(int, optional): The number of words in each chunk. Default is100.
Example usage:
chunker = FixedLengthWordChunking(chunk_size=100)
chunks = chunker.chunk("This is a sample text. It will be split into fixed-length word chunks.")SlidingWindowChunking
SlidingWindowChunking uses a sliding window approach to chunk a given text. Each chunk has a fixed length, and the window slides by a specified step size.
Constructor Parameters:
window_size(int, optional): The number of words in each chunk. Default is100.step(int, optional): The number of words to slide the window. Default is50.
Example usage:
chunker = SlidingWindowChunking(window_size=100, step=50)
chunks = chunker.chunk("This is a sample text. It will be split using a sliding window approach.")Extraction Strategies 🧠
NoExtractionStrategy
NoExtractionStrategy is a basic extraction strategy that returns the entire HTML content without any modification. It is useful for cases where no specific extraction is required.
Constructor Parameters:
None.
Example usage:
extractor = NoExtractionStrategy()
extracted_content = extractor.extract(url, html)LLMExtractionStrategy
LLMExtractionStrategy uses a Language Model (LLM) to extract meaningful blocks or chunks from the given HTML content. This strategy leverages an external provider for language model completions.
Constructor Parameters:
provider(str, optional): The provider to use for the language model completions. Default isDEFAULT_PROVIDER(e.g., openai/gpt-4).api_token(str, optional): The API token for the provider. If not provided, it will try to load from the environment variableOPENAI_API_KEY.instruction(str, optional): An instruction to guide the LLM on how to perform the extraction. This allows users to specify the type of data they are interested in or set the tone of the response. Default isNone.
Example usage:
extractor = LLMExtractionStrategy(provider='openai', api_token='your_api_token', instruction='Extract only news about AI.')
extracted_content = extractor.extract(url, html)CosineStrategy
CosineStrategy uses hierarchical clustering based on cosine similarity to extract clusters of text from the given HTML content. This strategy is suitable for identifying related content sections.
Constructor Parameters:
semantic_filter(str, optional): A string containing keywords for filtering relevant documents before clustering. If provided, documents are filtered based on their cosine similarity to the keyword filter embedding. Default isNone.word_count_threshold(int, optional): Minimum number of words per cluster. Default is20.max_dist(float, optional): The maximum cophenetic distance on the dendrogram to form clusters. Default is0.2.linkage_method(str, optional): The linkage method for hierarchical clustering. Default is'ward'.top_k(int, optional): Number of top categories to extract. Default is3.model_name(str, optional): The model name for embedding generation. Default is'BAAI/bge-small-en-v1.5'.
Example usage:
extractor = CosineStrategy(semantic_filter='finance rental prices', word_count_threshold=10, max_dist=0.2, linkage_method='ward', top_k=3, model_name='BAAI/bge-small-en-v1.5')
extracted_content = extractor.extract(url, html)TopicExtractionStrategy
TopicExtractionStrategy uses the TextTiling algorithm to segment the HTML content into topics and extracts keywords for each segment. This strategy is useful for identifying and summarizing thematic content.
Constructor Parameters:
num_keywords(int, optional): Number of keywords to represent each topic segment. Default is3.
Example usage:
extractor = TopicExtractionStrategy(num_keywords=3)
extracted_content = extractor.extract(url, html)Contributing 🤝
We welcome contributions from the open-source community to help improve Crawl4AI and make it even more valuable for AI enthusiasts and developers. To contribute, please follow these steps:
- Fork the repository.
- Create a new branch for your feature or bug fix.
- Make your changes and commit them with descriptive messages.
- Push your changes to your forked repository.
- Submit a pull request to the main repository.
For more information on contributing, please see our contribution guidelines.
License 📄
Crawl4AI is released under the Apache 2.0 License.
Contact 📧
If you have any questions, suggestions, or feedback, please feel free to reach out to us:
- GitHub: unclecode
- Twitter: @unclecode
- Website: crawl4ai.com
Let’s work together to make the web more accessible and useful for AI applications! 💪🌐🤖


What do you think?
Show comments / Leave a comment